MLOps at GenAI
Introduction
Welcome to the world of Generative AI and MLOps, where beginners often find themselves flooded with YT Videos but risk being trapped in beginners loop. I’m there too, and now I firmly believe in the power of public learning. Turning innovative ideas into reality requires action, not perfection, and this blog aims to guide you through the practicalities of applying MLOps principles to Generative AI (GenAI)
"Talk is cheap. Show me the code." - Linus Torvalds
Let’s dive into the challenges, setups, and the unique blend of engineering that make me so exciting last week.
Challenges
| GenAI | Discriminative AI |
|---|---|
| opens the doors to creative | not creative |
| bigger in nature | comparitively small |
| stable diffusion, LLMs | classification,regression |
Objective
I deployed Stable Diffusion model using 3$
Setup
Over the past few weeks, I tackled these challenges head-on while deploying Stable Diffusion—a state-of-the-art generative AI model—into production. Here’s the setup:
- clone the repo https://github.com/Muthukamalan/MLOps-at-GenAI and do docker !!!BANG!!!💥 That’s the power of reproducibility.
1
docker compose up --build -d
Yup, with AWS keys inplace.
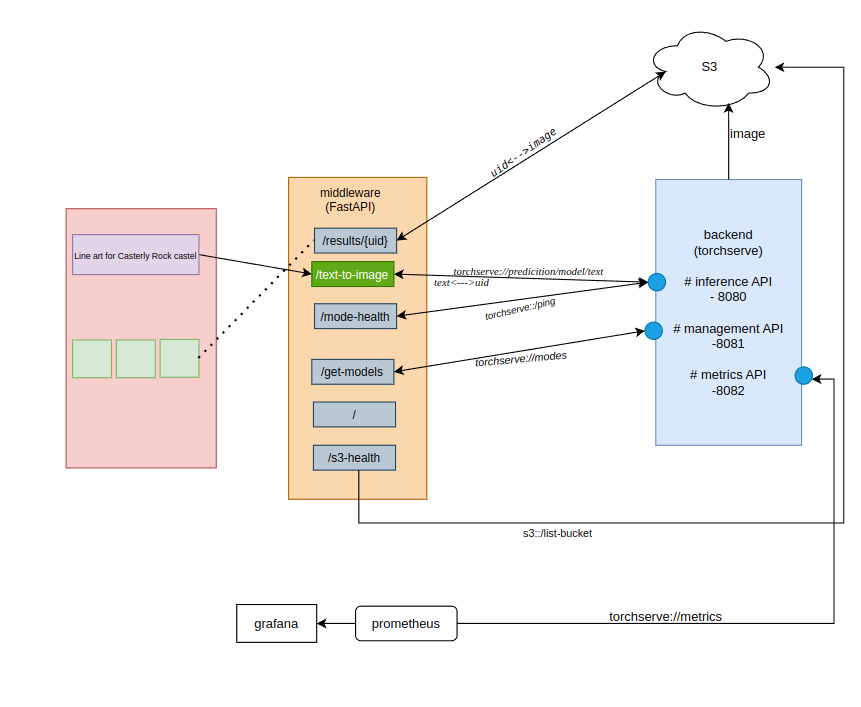
- Model Deployment TorchServe: Stable Diffusion was deployed using TorchServe, a scalable model-serving framework. This ensured the model was ready to handle production-scale requests.
- use, spot instance
g4dn.2xlarge“Linux Spot Average Cost - $0.2484 hourly” - Grant respective access “S3FullAccess” to able to access your S3 Bucket. we need later
- Pick a Image
cudnn9-runtimeandcuda121wihpytorch==2.5 - Artifact Storage: The model artifacts were stored on Amazon S3, enabling seamless accessibility and automated updates.
- visit instances-repo and give a star if you like it.
- use, spot instance
- Async API Wrapping
- Using FastAPI, I wrapped TorchServe APIs with asynchronous functionality, making the endpoints ultra-responsive and capable of handling concurrent requests like a champ. So It won’t hung up my main thread HOMEPAGE
- Frontend Integration
- Built an interactive frontend using Next.js, which dynamically pulled generated images from S3. This made the experience visually engaging and accessible for end-users.
- System Observability
- Integrated Prometheus and Grafana for monitoring system health. Real-time dashboards ensured transparency, stability, and actionable insights at every step.
- Reproducibility Simplified
- The entire stack was containerized with Docker Compose, ensuring anyone could reproduce the pipeline effortlessly, irrespective of their environment.
Overview
Project Structure
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
.
├── assets/
├── backend/
│ ├── config.properties
│ ├── Dockerfile.torchserve
│ ├── images
│ ├── logs
│ ├── metrics.yaml
│ ├── model_store
│ ├── notebook
│ ├── prompts.txt
│ ├── README.md
│ ├── requirements.txt
│ ├── sd3_handler.py
│ └── swagger.json
├── frontend/
│ ├── app
│ ├── components
│ ├── config
│ ├── Dockerfile.next
│ ├── lib
│ ├── next.config.js
│ ├── next-env.d.ts
│ ├── node_modules
│ ├── package.json
│ ├── package-lock.json
│ ├── postcss.config.js
│ ├── public
│ ├── README.md
│ ├── tailwind.config.ts
│ ├── tsconfig.json
│ └── types
├── grafana/
├── middleware/
│ ├── app.py
│ ├── Dockerfile.fastapi
│ └── requires.txt
├── prometheus/
│ ├── prometheus.yml
│ └── README.md
├── mindmap.drawio
├── LICENSE
├── compose.yaml
├── pyproject.toml
└── README.md
backend:: Torchserve
1
2
3
4
5
6
inference_address=http://0.0.0.0:8080
management_address=http://0.0.0.0:8081
metrics_address=http://0.0.0.0:8082
install_py_dep_per_model=false # remainder for overhead
metrics_mode=prometheus
job_queue_size=50
For this experiment I loaded the small-diffusion-Model from HF.co/ with bfloat16
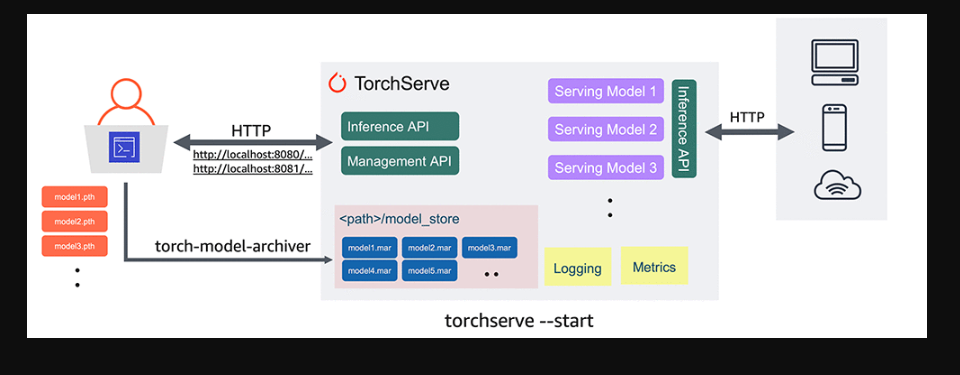
TorchServe plays a crucial role in the production deployment of PyTorch models:
Model Packaging: Models are packaged into TorchServe-friendly formats, including .mar (Model Archive) files, which contain both the model artifacts and associated metadata.
Deployment Configuration: TorchServe allows developers to configure deployment settings such as the number of instances, batch size, and GPU usage. These configurations can be adjusted based on the expected workload.
Scaling and Load Balancing: TorchServe supports horizontal scaling by launching multiple instances of the same model, distributing incoming requests among them. This ensures that the system can handle increased traffic without sacrificing performance.
Monitoring and Management: Built-in monitoring features help track the health and performance of deployed models. This includes metrics like latency, throughput, and error rates. Operators can use this information to make informed decisions about resource allocation and scaling.
Continuous Integration/Continuous Deployment (CI/CD): TorchServe can be integrated into CI/CD pipelines, automating the deployment and versioning of models whenever new updates are available.
- Inference API (8080/predicition/) for generating images.
- Management API (8081/models/{model-name}) for model loading and administrative tasks.
- Metrics API (8082/metrics/) for monitoring performance.
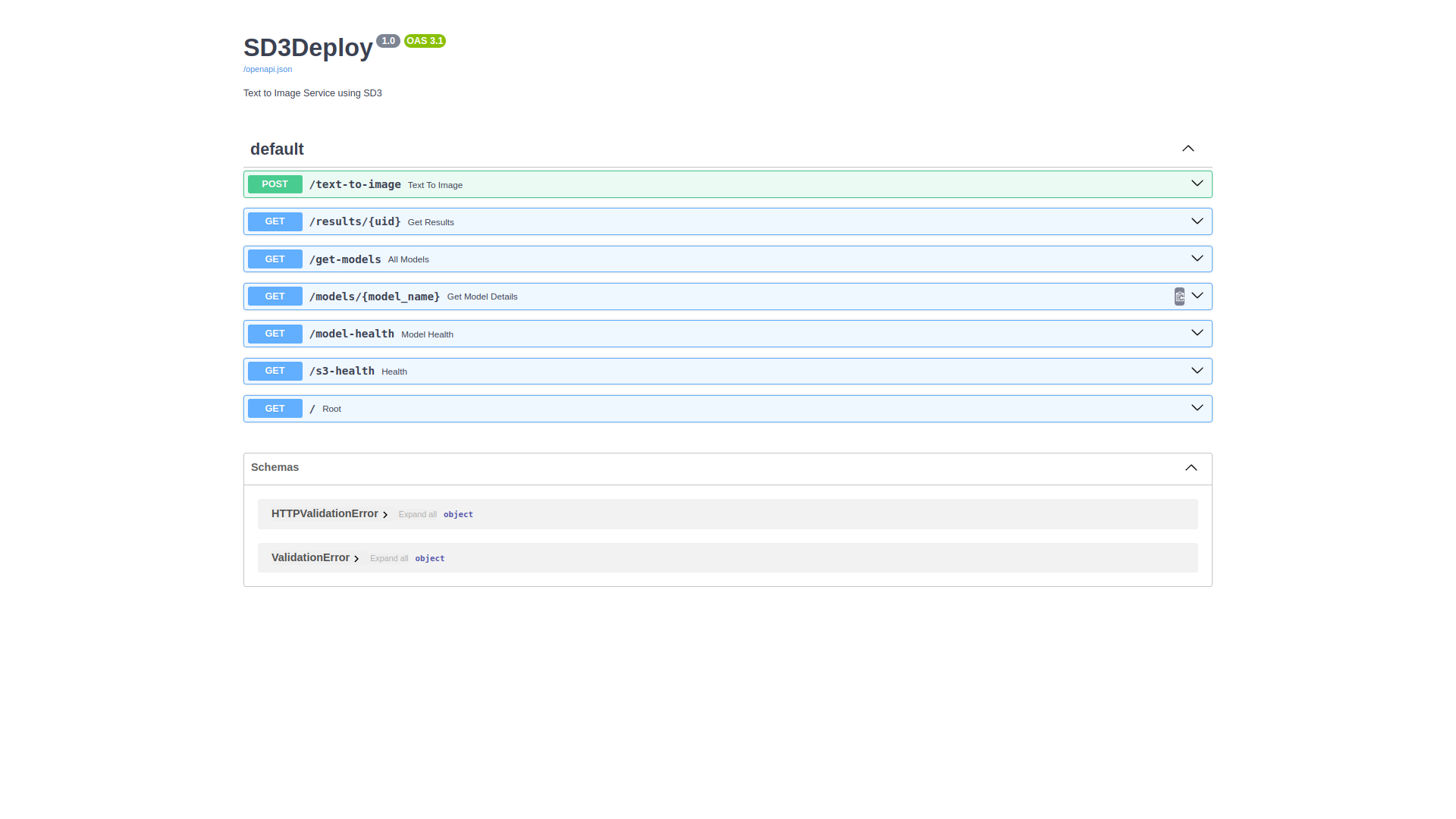
FastAPI
FastAPI is a modern, high-performance, Python web framework for building APIs. It’s designed for speed and ease of use, leveraging Python type hints to provide automatic validation and OpenAPI documentation generation.
Asynchronous Support: FastAPI supports async/await, enabling it to handle multiple requests concurrently. This is critical when serving Generative AI models, which often involve time-consuming inference.
Performance: FastAPI is built on Starlette and Pydantic, ensuring lightning-fast performance comparable to Node.js frameworks like Express.
Ease of Use: Automatic generation of OpenAPI documentation allows developers to interact with APIs effortlessly.
Scalability: Its lightweight and async-first design makes it a perfect fit for high-scale production workloads.
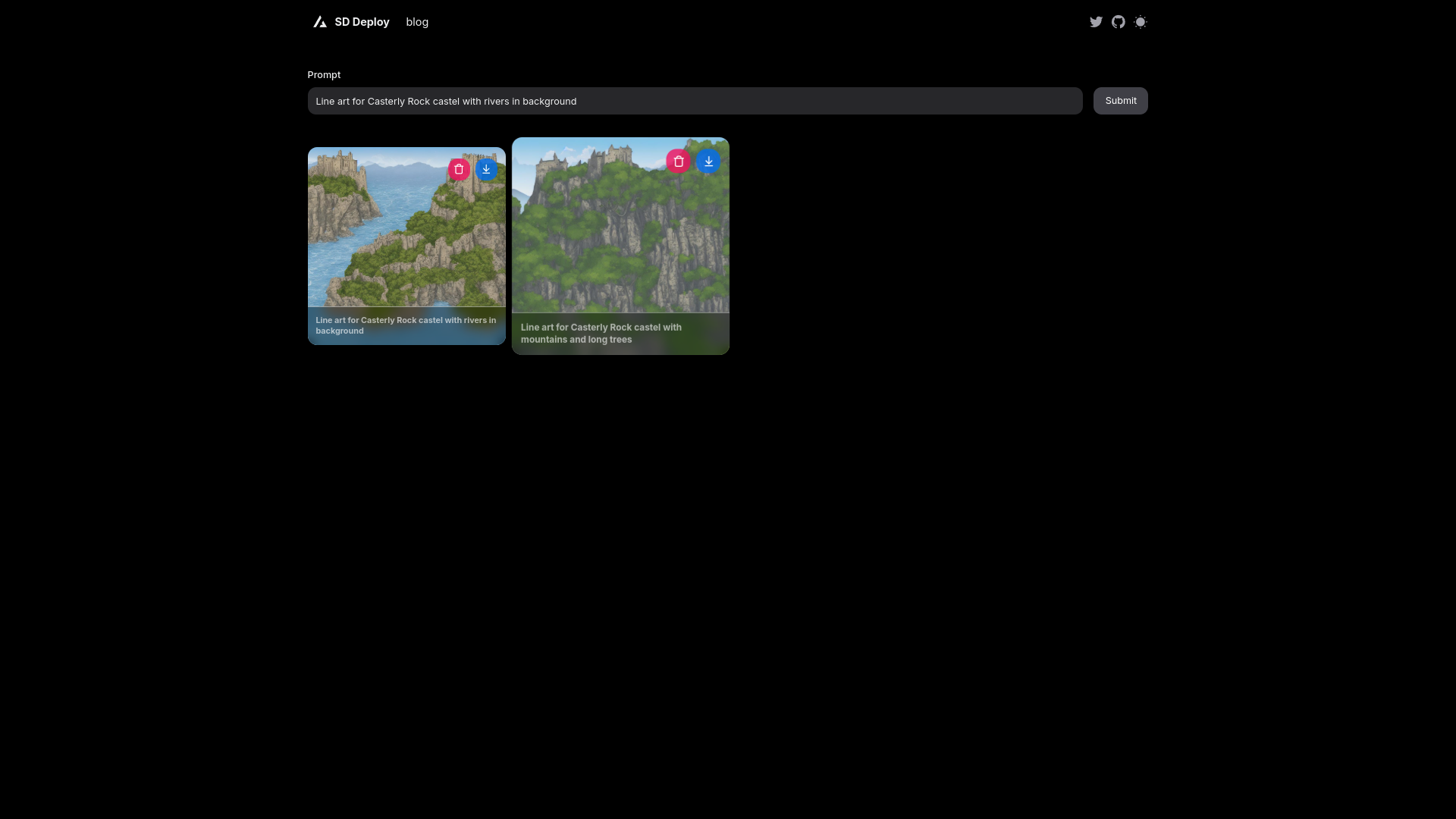
- /text-to-image: Receives user text prompts and forwards them to the backend TorchServe API for inference.
- /results/{uid}: Retrieves results (e.g., generated images) stored in S3.
- Health-check endpoints (/mode-health, /s3-health) to ensure the system is up and running.
Amazon S3:
Acts as a central repository for storing generated images and model artifacts. Middleware pulls images dynamically from S3 for user consumption.
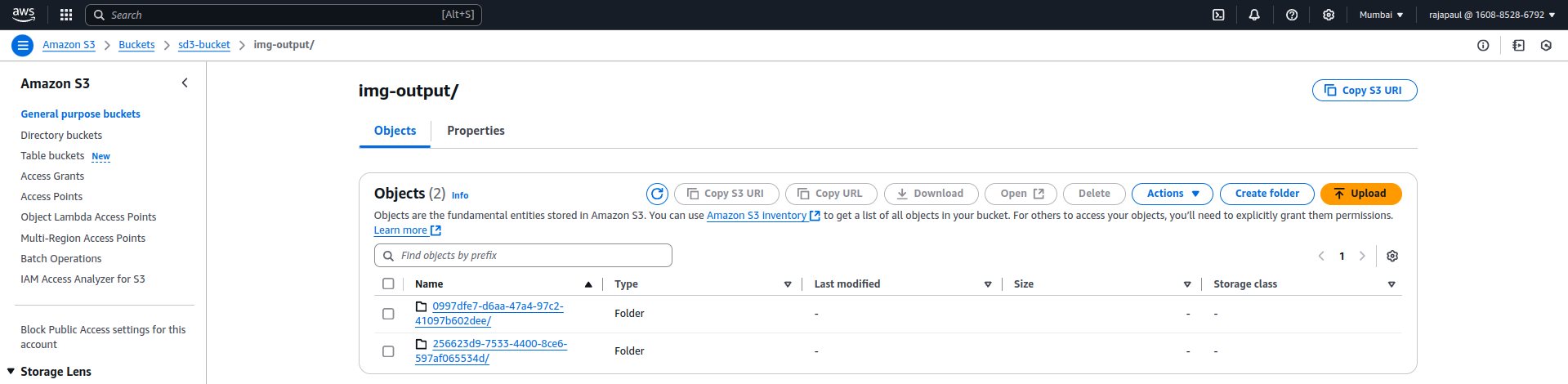
1
2
3
4
5
6
7
8
9
# temperaory url to show image to public
s3_client.generate_presigned_url(
"get_object",
Params={
"Bucket": BUCKET_NAME,
"Key": result["result"]
},
ExpiresIn=3600 * 24, # 24 hours
)
System Monitoring:
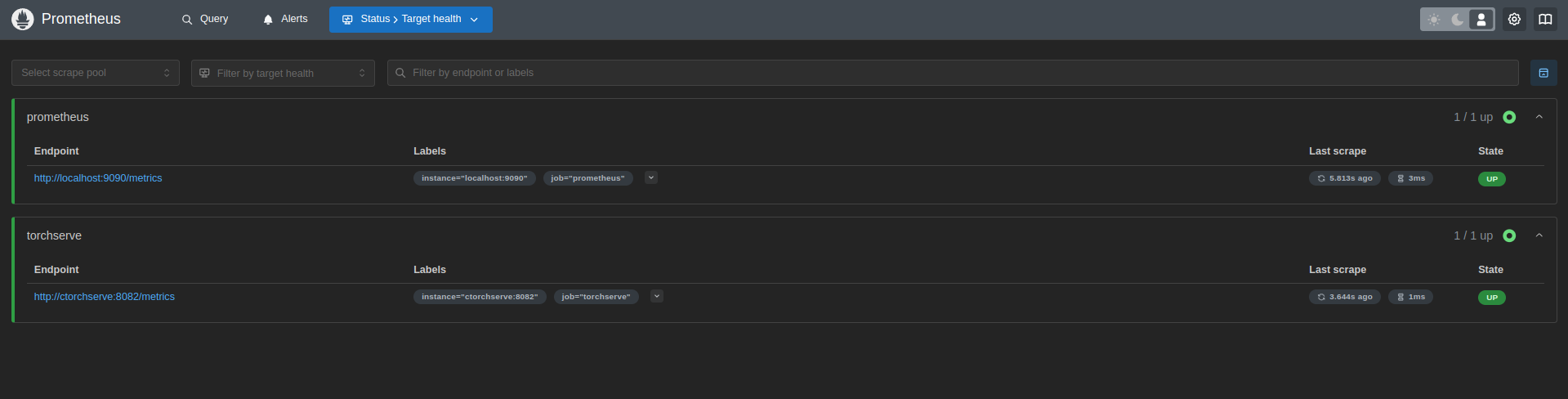
- Metrics are exposed by TorchServe and collected by Prometheus.
- Grafana visualizes these metrics for real-time system observability.
Reproducibility:
- The entire setup is containerized using Docker Compose for easy replication across environments.
Frontend
In Industrial practise we won’t do much everything, web developers can take care from here.
I took boilerplate code from nextjs-repo