MLOps 101
MLOps 101
Building a Machine Learning Model is tedious, Yet, the payoff is worth it, especially when the system you’re building aligns with business objectives and adds intelligence to decision-making processes.
If model doesn’t meet its intended objectives, the journey yields valuable learnings that can guide future improvements. 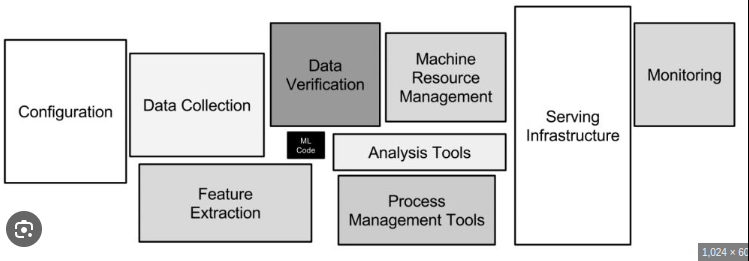
Technology used:
pytorch-lightning:: Framework build on top ofpytorch⚡DVC:: Data Managment ToolHydra ⚙️:: Configs Managment ToolTensorboard:: Visualization ToolDocker🐳 andCompose:: Shipping ContainersGradio:: UIGitHub Actions:: Continous Integration and Continous DeploymentAWS ☁️::- IAM:: Manage Permissions and Roles
- S3:: Store Artifacts
- EC2:: Compute Resource to Training Model
- ECR:: Similar to DockerHub
- Lambda:: Serverless compute
- CDK:: Cloud Development Kid as easy deploy for cloudFormation
pre-requisties:
pretty much to code in python and MNIST in torch
checkout the code here:: DogBreedsClassifier 🐕
Setup 1: Setting up DVC🗃️
git is not indent to store large binary files, but git-lfs does. But there are subtle difference when it comes to DVC especially on binary files like image,audio,tensors.
It stores md5 hash value on Remote-server::[AWS-S3 Backend] and should manage by SCM git here 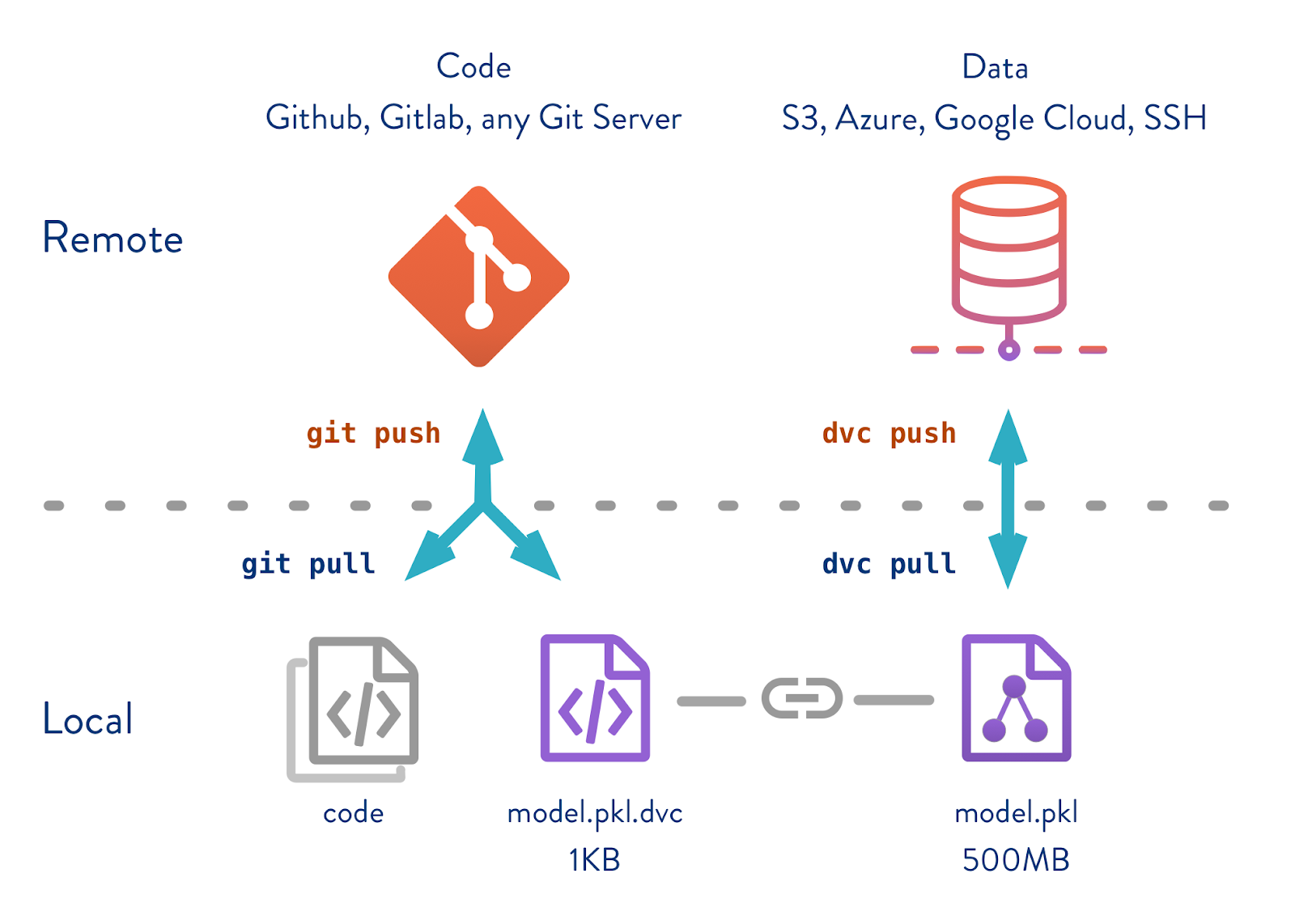
1
2
3
4
5
git init && dvc init
dvc add path/data_folder/
dvc remote add -d myremote s3://bucket-name
dvc push
dvc pull
- more on:: difference in DVC vs Git
Setup 2: AWS☁️
AWS Cost Management is a ART to manage it
Configure AWS and CDKon command-line terminal and giving permission to it.
1
2
3
4
5
6
7
8
9
10
11
12
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
sudo apt install unzip -y
unzip awscliv2.zip
sudo ./aws/install
aws --version
# configuration
aws configure -list
export CDK_DEFAULT_ACCOUNT=$(aws sts get-caller-identity --query Account)
export CDK_DEFAULT_REGION=$(aws configure get region)
IAM user must have certain Permission Policies. So, they’ll have to push artifacts to S3 and Pull ECR from
1
2
3
- AdministratorAccess
- AmazonElasticContainerRegistryPublicFullAccess
- AmazonS3FullAccess
Setup 3: GitHub Secrets & Configure EC2
Place you track all your code and GitHub-Action kicks starts on-push to your repo.
On train and test pipeline we need compute EC2 machine. run it on your hosted-machine to listen
1
2
3
4
5
6
7
8
9
# OS:: Linux
# Architecture:: X64
# Name: g4dn.xlarge
mkdir actions-runner && cd actions-runner ## create a folder
curl -o actions-runner-linux-x64-2.321.0.tar.gz -L https://github.com/actions/runner/releases/download/v2.321.0/actions-runner-linux-x64-2.321.0.tar.gz ## Download latest runner
echo "HASH-VALUE actions-runner-linux-x64-2.321.0.tar.gz" | shasum -a 256 -c ## validate the hash
tar xzf ./actions-runner-linux-x64-2.321.0.tar.gz ## extract the installer
./config.sh --url https://github.com/Muthukamalan/repo --token TOKENS ## Create the runner and start the configuration experience
./run.sh & ## Last step, run it!
add it Github Workflow to listen
1
runs-on: self-hosted

Setup 4: Hydra configs
Configuration apart from your source code and make use it in command-line it best-pratice. Hydra will do it for ourself. Can be overriden through CLI also.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
configs/
├── callbacks
│ └── default.yaml # early-stop, lr-monitor, model-checkpoint
├── data
│ └── dogs.yaml
├── experiment
│ ├── hparams.yaml # optimizing search grid by `Optuna` TPEsampler
│ └── pretrain.yaml # make torchscript model `script=true`
├── hydra
│ └── default.yaml
├── logger
│ └── tensorboard.yaml # csv, mlflow
├── model
│ └── mamba.yaml # mambda with different hparams
├── paths
├── trainer
│ └── default.yaml
├── __init__.py
├── eval.yaml
└── train.yaml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
hydra:
mode: "MULTIRUN"
launcher:
n_jobs: 1
sweeper:
sampler:
_target_: optuna.samplers.TPESampler
seed: 32
n_startup_trials: 3 # number of random sampling runs before optimization starts
direction: minimize # we use test_metrics['test/loss_epoch']
study_name: optimal_searching
n_trials: 2 ## number of possible combination you wanna try
n_jobs: 16 # threads
params:
# https://github.com/facebookresearch/hydra/discussions/2906
model.dims: choice([6,12,24,36],[12,24,48,72])
model.depths: "[3,3,15,3],[3,4,27,3], [3,3,9,3]"
model.head_fn: choice('norm_mlp','default')
model.conv_ratio: choice(1,1.2,1.5)
data.batch_size: choice(16,32,64)
hydra helps to run program with multiple combination of hyperparameters.
setup 5: Tensorboard
Most of Data Science work doing data clean-up and visualising all along the way. There are ton of tools out there.
- tensorboard
- mlflow
- aim
- neptune
Training
Pytorch-lightning wraps your internal training grad and train-loop and optimization step.
If you’re an EC2 machine g4dn.xlarge or single T4 instance with 256Gb storage run
1
docker compose up train
or in a local setup with respective GPU
1
2
make hparams # to hparams search
make train # to train model
Attaching Hardware work horse to make sure proper utilisation of Instance during faster training and inference.
- io operations
- CPU usage
- GPU usage
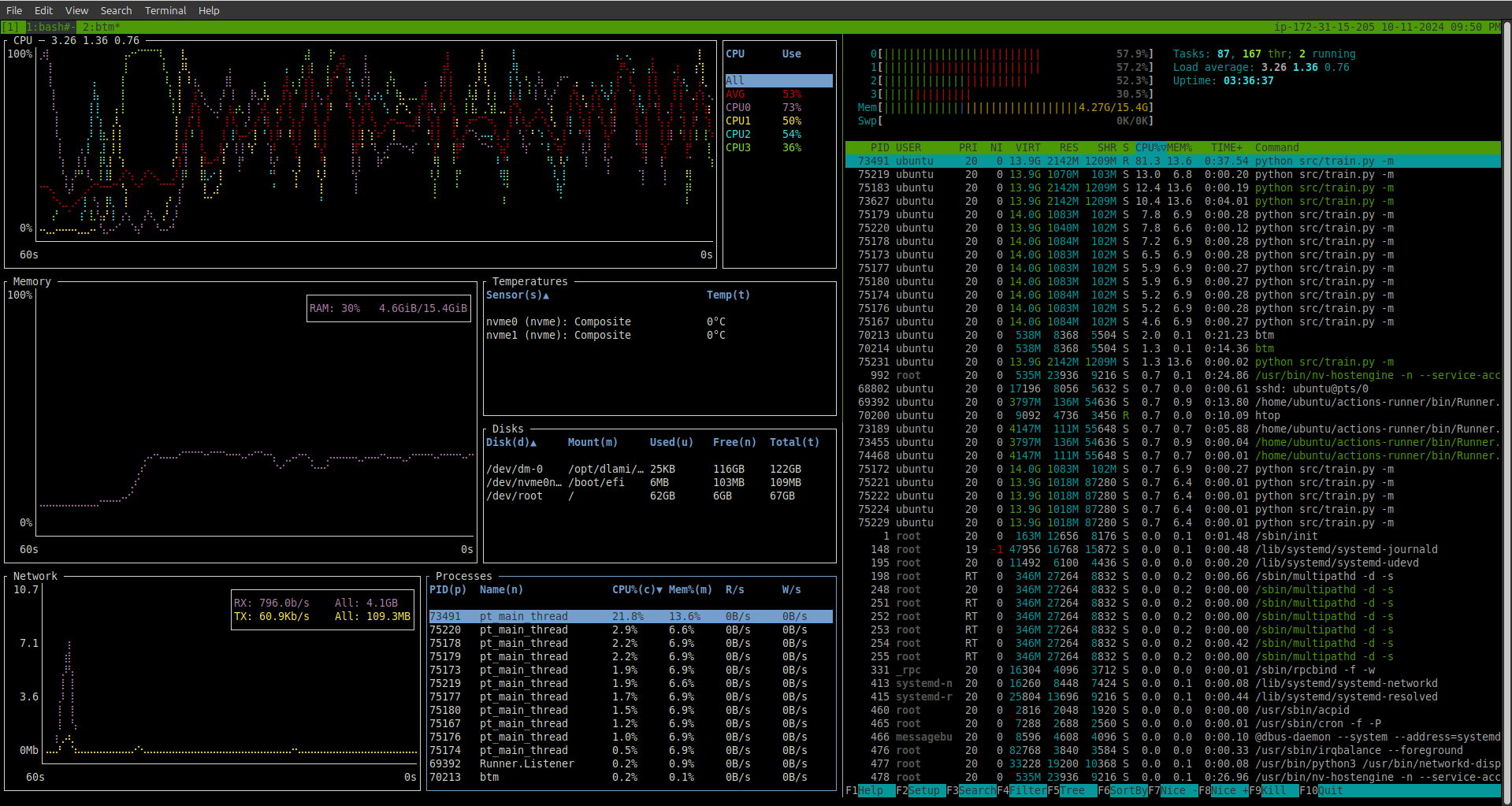
While doing Hyperparameter Search we’re monitoring
- Loss
- accuracy
- Learning-Rate
- ..
In parallel co-ordination plot will see possible combination of hparams we tired on 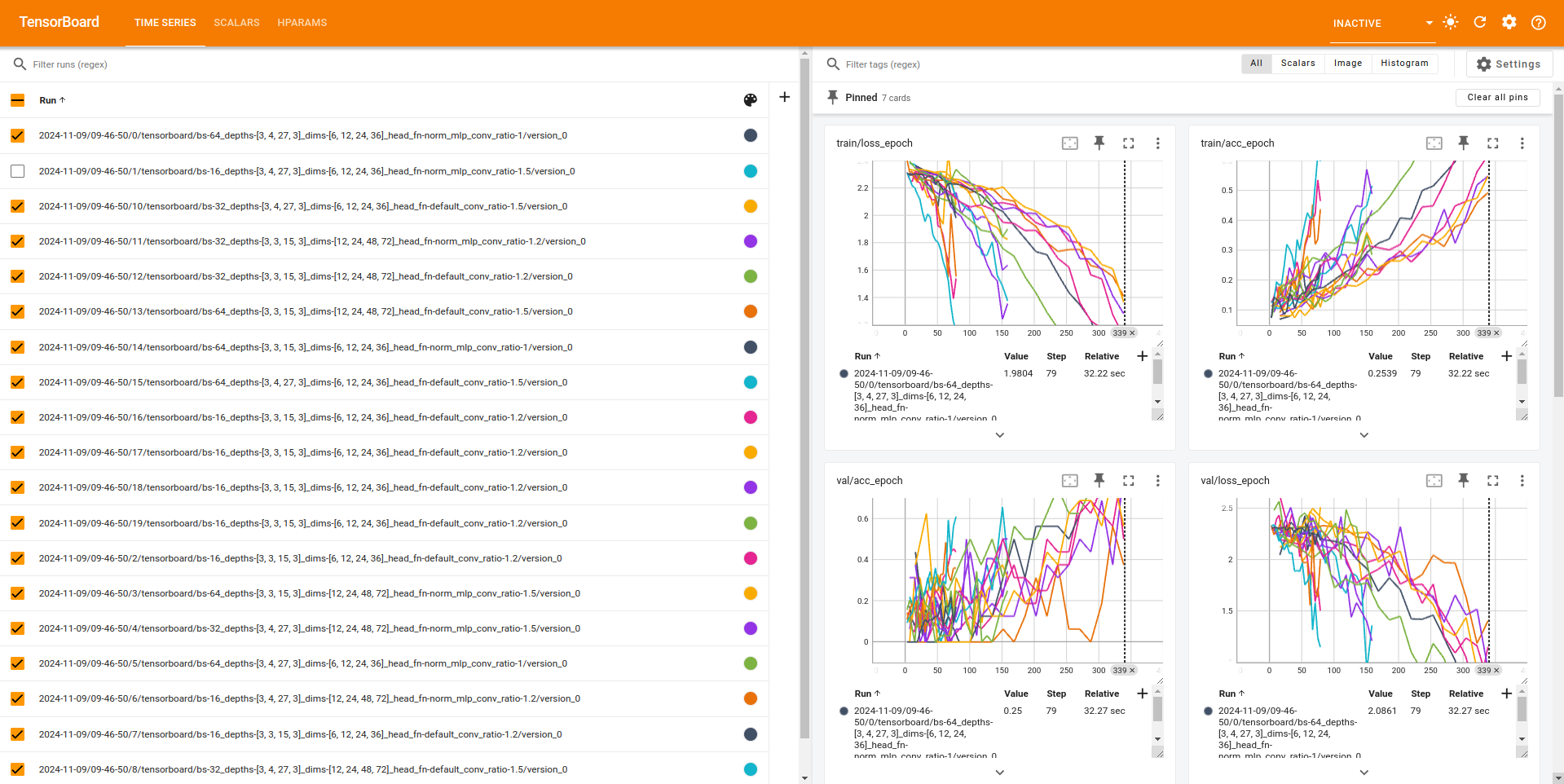
Test-Pytest
CODE-Coverage help to visuall show how much test-cases covered for model:: unittest, input and output size checks and more.
Evalution
We are testing the torch-scripted model and doing confusion matrix for training, testing and validation dataset
1
2
3
4
5
6
7
trainer.test(model, datamodule, ckpt_path=trainer.checkpoint_callback.best_model_path )
plot_confusion_matrix(
model=model,
datamodule=datamodule,
path=os.path.join(Path(cfg.paths.root_dir), "assets", ""),
)
| Training Dataset | Testing Dataset | Validation Dataset |
|---|---|---|
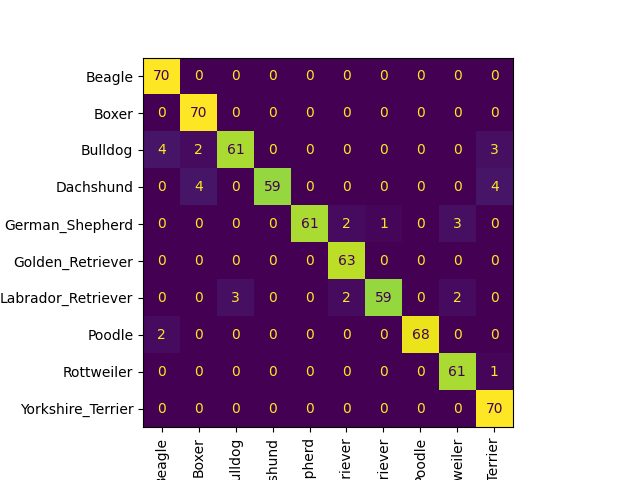 | 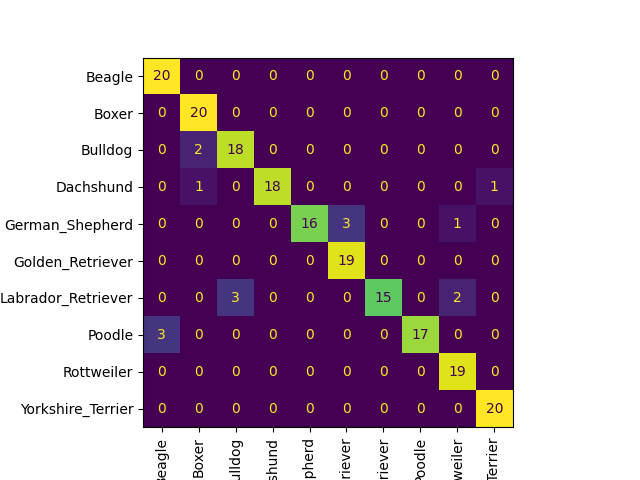 | 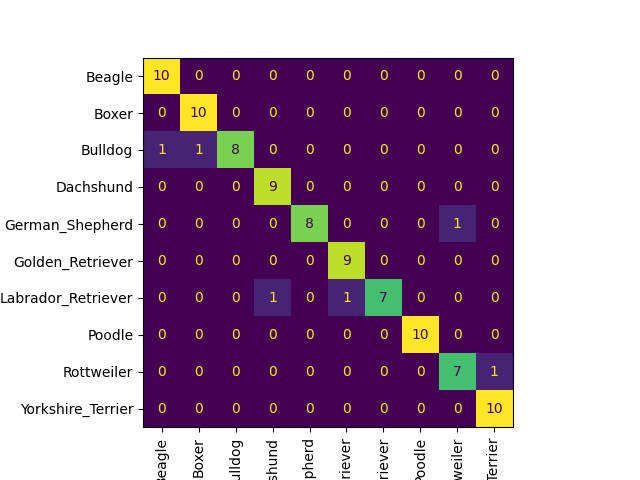 |
Inference
Huggingface offers free to deploy our model and interactive UI with minimal amount of boilerplate
Added a worflow on GitHub Actions to push model to gradio-spaces
- Deploy on Huggingface Gradio:: DogBreeds Classification
1
gradio deploy
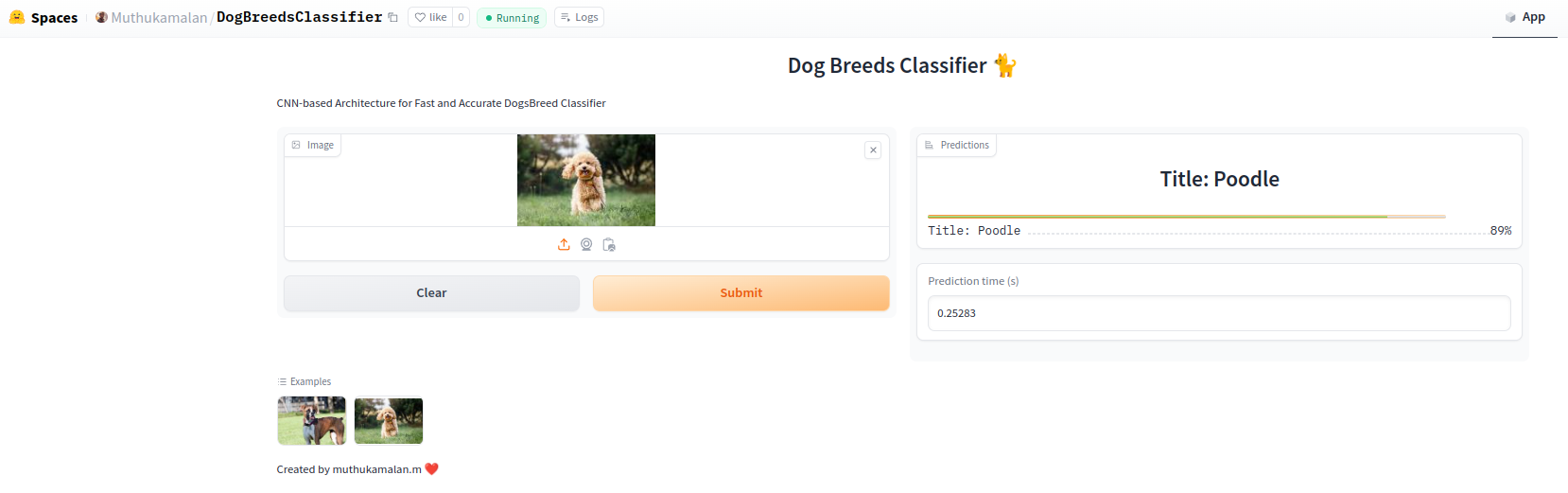
Once the model been trained , we saving copy torchscripted model in gradio/ folder. Will be load by torch later
1
2
model = torch.jit.load('best_model.pt',map_location=device)
outputs= model(inputs)
- Deploy on LAMBDA Function
1
2
3
# requirements to run CDK
aws-cdk-lib==2.170.0
constructs>=10.0.0,<11.0.0
To make it simple we use lambda-web-adapter to ease deployment on aws lamdda, where web server binaries should be in /opt/extensions/ directory.
check gradio-web-adapter
1
2
3
4
5
6
7
8
9
10
FROM public.ecr.aws/docker/library/python:3.11.10-slim
# Install AWS Lambda Web Adapter
COPY --from=public.ecr.aws/awsguru/aws-lambda-adapter:0.8.4 /lambda-adapter /opt/extensions/lambda-adapter
ENV PORT=8000
WORKDIR /code
COPY requirements.txt .
RUN pip install -r requirements.txt
COPY . .
EXPOSE 8000
CMD [ "python","app.py"] # make sure app runs 8000 port
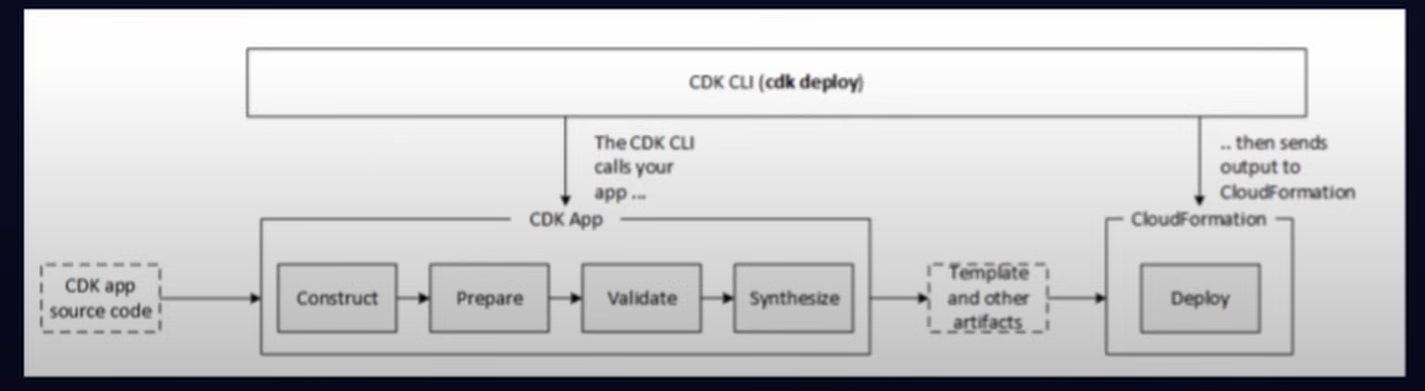
1
{ "app": "python3 cdk.py"}
To deploy on lambda function on AWS
1
2
cdk deploy --verbose
cdk destroy
If the files are not been empty, In here, ECR we pushed Dockerfile ot don’t delete. Make sure check for unnecessary credit bills.